Video Object Detection with an Aligned Spatial-Temporal Memory
Presented in ECCV 2018
People
Abstract
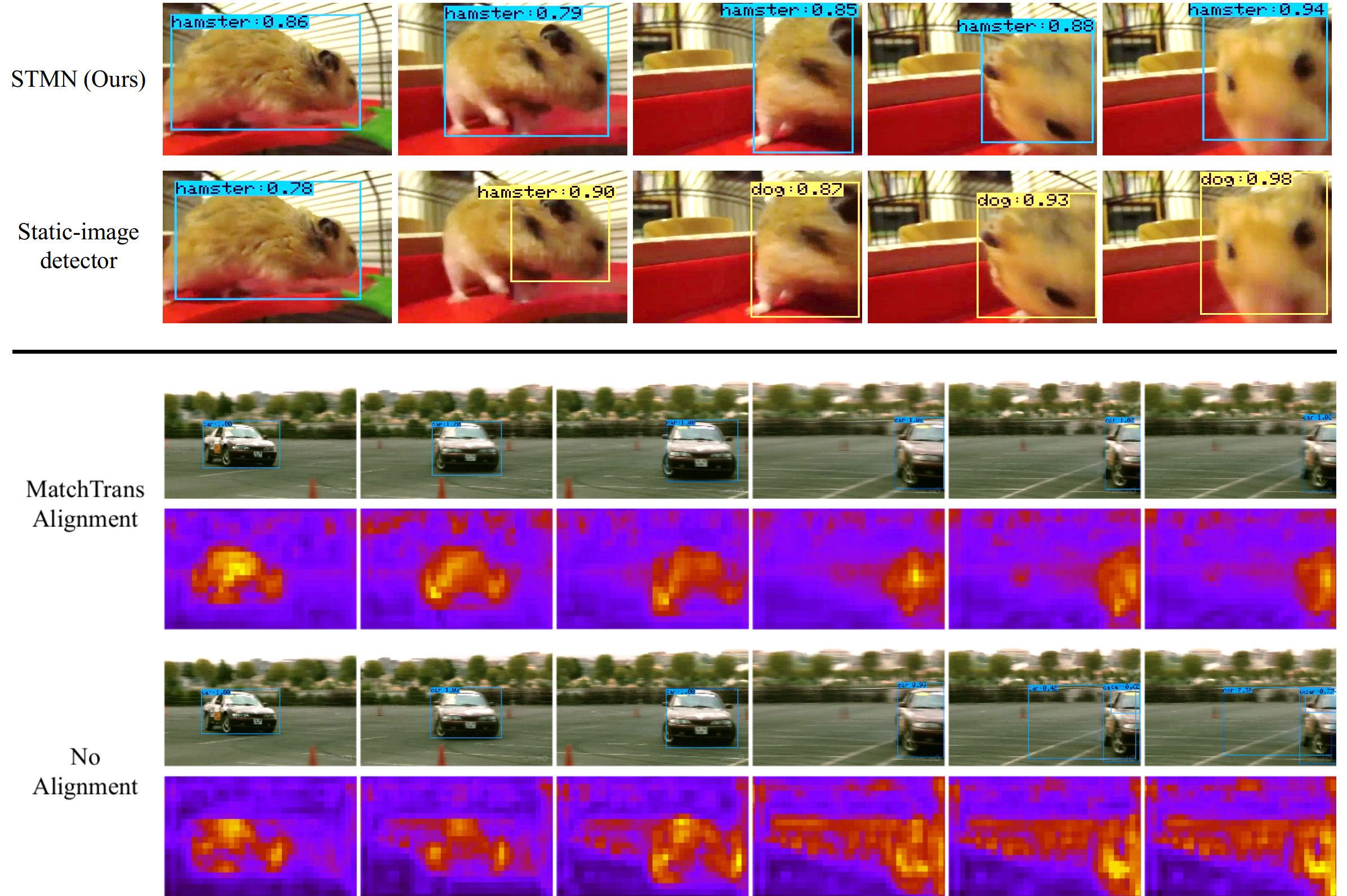
We introduce Spatial-Temporal Memory Networks for video object detection. At its core, a novel Spatial-Temporal Memory module (STMM) serves as the recurrent computation unit to model long-term temporal appearance and motion dynamics. The STMM's design enables full integration of pretrained backbone CNN weights, which we find to be critical for accurate detection. Furthermore, in order to tackle object motion in videos, we propose a novel MatchTrans module to align the spatial-temporal memory from frame to frame. Our method produces state-of-the-art results on the benchmark ImageNet VID dataset, and our ablative studies clearly demonstrate the contribution of our different design choices.
Paper
|
|
Additional materials
Source Code
Acknowledgments
This work was supported in part by the ARO YIP W911NF17-1-0410, NSF CAREER IIS-1751206, AWS Cloud Credits for Research Program, and GPUs donated by NVIDIA. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of ARO or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
Comments, questions to Fanyi Xiao