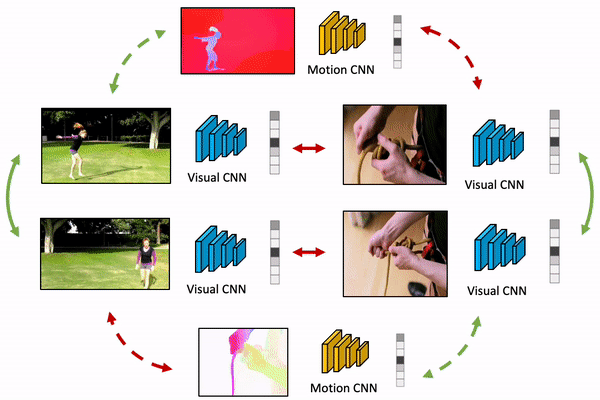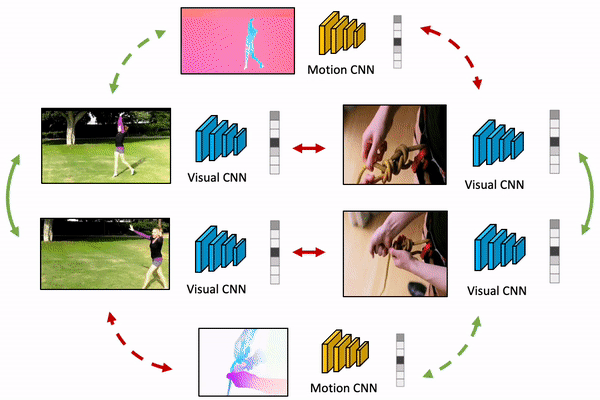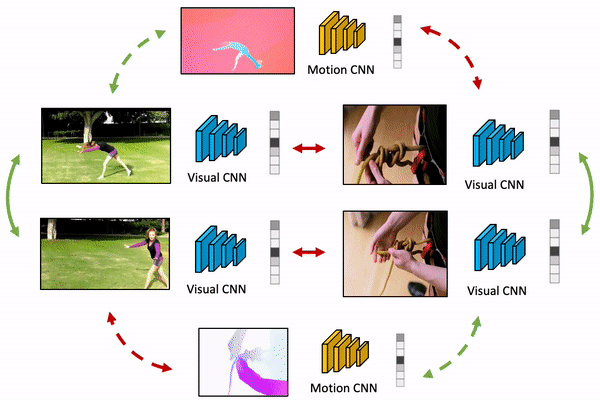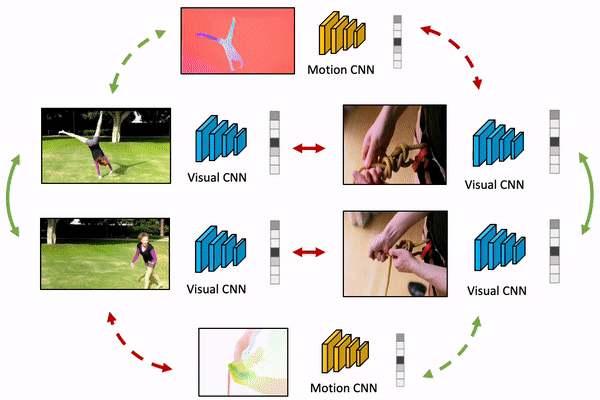
We present MaCLR, a novel method to explicitly perform cross-modal self-supervised video representations learning from visual and motion modalities. Compared to previous video representation learning methods that mostly focus on learning motion cues implicitly from RGB inputs, MaCLR enriches standard contrastive learning objectives for RGB video clips with a cross-modal learning objective between a Motion pathway and a Visual pathway. We show that the representation learned with our MaCLR method focuses more on foreground motion regions and thus generalizes better to downstream tasks. To demonstrate this, we evaluate MaCLR on five datasets for both action recognition and action detection, and demonstrate state-of-the-art self-supervised performance on all datasets. Furthermore, we show that MaCLR representation can be as effective as representations learned with full supervision on UCF101 and HMDB51 action recognition, and even outperform the supervised representation for action recognition on VidSitu and SSv2, and action detection on AVA.
Paper
MaCLR: Motion-aware Contrastive Learning of Representations for Videos
@article{xiao-modist2021,
title={MoDist: Motion Distillation for Self-supervised Video Representation Learning},
author={Fanyi Xiao and Joseph Tighe and Davide Modolo},
journal={arXiv preprint arXiv:2106.09703},
year={2021}
}